Implementation and Analysis of Stack and Queue
- Course: Data Structures
- StudentID: 2466044
- Author: LEE SIEUN
- Date: 2025-10-18
- Repository(public): 2025-Data-Structures Repository/04-Assignment
Assignment Goals
Re-implement the functions in `linked_stack.cpp` using a circular doubly linked list. Revise Simulation.cpp, which is implemented with the assumption of a single bank teller, for the case where two tellers work. Then, print the results using the print_stat() function.
- Re-implementation the functions in the code('linked_stack.cpp') using `circular doubly linked list`.
- Revise 'Simulation.cpp', which is implemented with the assumption that there is a single bank staff, for the case where two bank staffs work. Then, print out the results using `print_stat()` in the code.
#1. Introduction(Theoretical Background, Logic)
Please refer to the Appendix (link) for detailed explanations.
The content is long, so it is attached as a reference.
Please visit the post below.
"[자료구조] Stack, Queue" : https://sihyes.tistory.com/129
"[자료구조] List” : https://sihyes.tistory.com/117
The data structure we are about to implement is a stack.
A stack follows the concept of LIFO (Last-In First-Out),
meaning the most recently added data is the first to be removed.
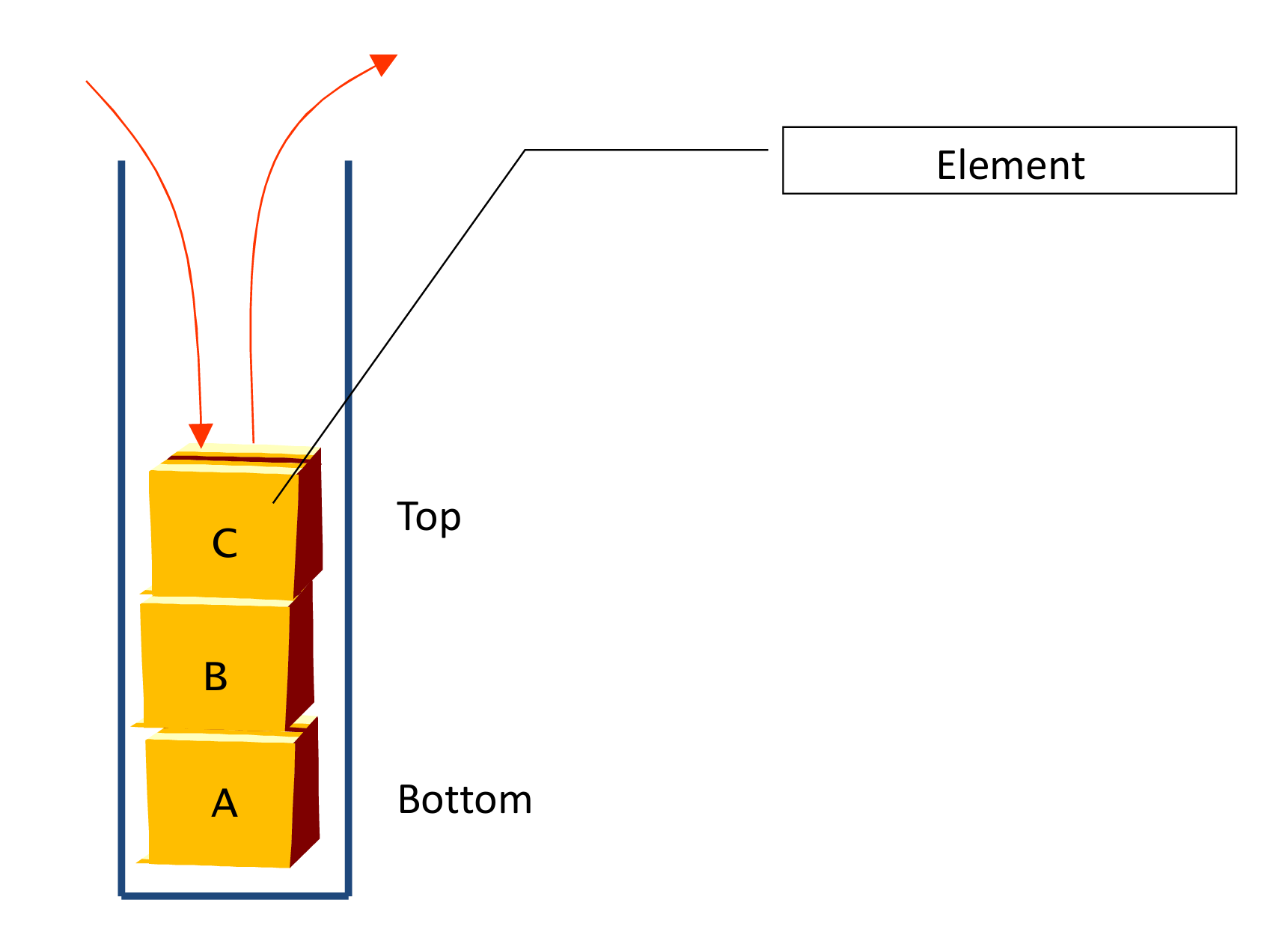
Abstract Data Type (ADT) of Stack
Object: a linear list of n elements.
Operations:
- `create()` ::= Create a stack
- `push(s,e)` ::= Add element 'e' th the top of the stack
- `peek(s)` ::= Returns the element at the top of the stack without deleting it.
- `pop(s)` ::= Return element at the top of the stack and then deletes it
- `is_empty(s)` :: = Checks if the stack 's' is empty
Here is an example of a stack application: the Undo function in an editor.
This function remembers the previous state or return address of a function call.
(The same logic is used for the Ctrl + Z feature.)
There are two ways to implement a stack:
one using an array, and the other using a linked list.
When using an array,
- Pros: The implementation is simple, and insertion/deletion is fast.
- Cons: The stack size is limited.
When using a linked list,
- Pros: The stack size is not limited.
- Cons: The implementation is more complex, and insertion/deletion takes longer.
Then, What is Queue?

The data structure we are about to implement is a queue.
A queue follows the concept of FIFO (First-In First-Out), meaning the first element added is the first to be removed.
Abstract Data Type (ADT) of Queue
Object: a linear list of n elements.
Operations:
- `create()` ::= Create a queue
- `enqueue(q,e)` ::= Add element 'e' to the rear of the queue
- `dequeue(q)` ::= Remove and return the element at the front of the queue
- `front(q)` ::= Returns the element at the front without removing it
- `rear(q)` ::= Returns the element at the rear without removing it
- `is_empty(q)` ::= Checks if the queue 'q' is empty
Here is an example of a queue application: a line of people waiting for service at a bank. The first person in line is the first to be served. Queues are widely used in scheduling systems (CPU, printer, network packets) and simulations (e.g., bank service, traffic flow).
There are two common ways to implement a queue: using an array or using a linked list.
When using an array:
- Pros: Simple implementation, direct indexing of elements
- Cons: The queue size is limited; may require shifting elements
When using a linked list:
- Pros: Queue size is not limited; insertion and deletion are flexible
- Cons: Implementation is more complex; accessing elements takes longer
There are also several variants of queues:
- Circular Queue – connects the rear to the front to efficiently reuse space
- Linked Queue – allows dynamic memory allocation, can be priority-based
- Deque (Double-ended Queue) – allows insertion and deletion from both ends
| Feature | Description |
| Data Access Order | FIFO (First-In, First-Out) |
| Main Operations | enqueue(), dequeue(), front(), rear() |
| Implementation | Array, Linked List, or Circular Queue |
| Advantage | Models real-world waiting lines; efficient for sequential processing |
| Disadvantage | Cannot directly access middle elements; may require extra handling for overflow in array-based queues |
#2. Problem Definition
In this assignment, two different implementations are required:
1. (Programming)
The attached code (‘linked_stack.cpp’) was implemented using simple linked list. Re-implement the functions in the code using circular doubly linked list which is defined as below, and then run the main function of the code.
typedef struct DlistNode {
element data;
struct DlistNode *llink;
struct DlistNode *rlink;
} DlistNode;
2. (Programming)
The attached code (‘Simulation.cpp’) was implemented with the assumption that there is a single bank staff. Revise the code accordingly in case that two bank staffs work, and then print out the results using ‘print_stat()’ in the code. Note) A relatively large should be set to obtain meaningful results.
#3. Algorithm and Data Structure
In this project, the main data structures used are linked lists, including circular and doubly linked lists.
In a doubly linked list, each node contains data and two pointers (`llink` and `rlink`) that enable bidirectional traversal.
In a circular doubly linked list, the `rlink` of the final node is connected back to the head node, and the `llink` of the head node points to the last node.
This structure allows continuous access to both the first and last nodes through the head node, without needing to traverse the entire list.
In the first code (`DoublyLinkedStack.cpp`), the implementation follows the structure of a circular doubly linked list.
A head node is first created, with both its left and right links pointing to itself.
When inserting a new node, its left link points to the head node, and its right link points to the node that was previously to the right of the head.
After linking the new node, the neighboring nodes are updated accordingly — the former right node’s left link now points to the new node, and the head node’s right link is updated to connect to the newly inserted node.
The pop operation follows the same logic in reverse:
it disconnects the node at the top of the stack (right of the head), updates surrounding links, and then returns the removed data.
For the queue-based simulation, the key concept is FIFO (First In, First Out).To simulate two bank staff members, two separate `service_time` variables were initialized.Each `service_time` represents the service duration for one staff member.
When a staff member finishes serving a customer (`service_time` reaches zero), a new customer is dequeued and assigned.
In this model, both staff share a single waiting queue, but operate independently in handling customers.
This effectively reduces the total waiting time by allowing parallel service.
#4. Implementation Results and Analysis
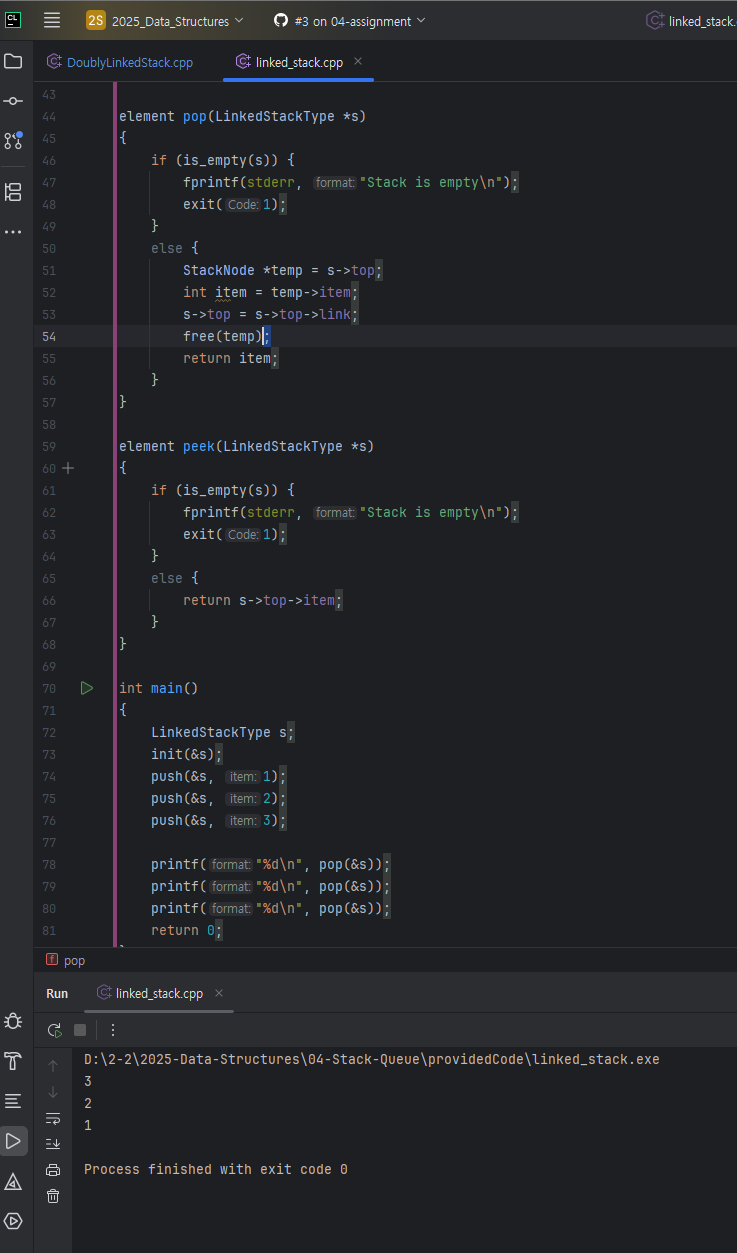
4.1 Re-implementation using a circular doubly linked list.
First, we need a `head_node` . Using `init()`, we create the `head_node` at `s->top`. Both its `rlink` and `llink` point to itself (`s->top`).

Second, the `empty()` method should be changed to check the condition, `s->top->rlink == s->top`. Previously, we checked whether` s->top` was `NULL`, but now we deterimine emptiness based on whether the `head_node` points to itself.

Third, the `push()` method works the same way as a doubly linked list insertion.

Fourth, `pop()` method. it is similar to the doubly linked list `delete()`, but with a small difference.
The added line is line 56 : `s->top->rlink = temp->rlink`. This is because we always pop from the `head_node`’s right link (the top of the stack!).

After these changes, the stack runs correctly.

4.2 Implement Bank simulation when the number of staff is two.
The simulation program models a bank service system two staff members and customers arriving randomly.
The main components are:
- Customer Structure
Each customer is represented by a structure containing:- `id` unique identifier
- `arrival_time` the time the customer arrives
- `service_time` the time required to serve the customer
- Queue Implementation
A circular queue is used to store waiting customers.
This queue ensures FIFO (First-In, First-Out) order: the first customer to arrive is the first to be served.
Functions implemented:- `enqueue()` add a customer to the rear of the queue
- `dequeue()` remove a customer from the front of the queue
- `is_empty()` /` is_full()` detect the queue state
- Service Management
Each bank staff member has a service_time counter, representing the remaining time to finish the current customer.- If `service_time > 0`, the staff continues serving the current customer.
- If `service_time == 0`, the staff dequeues the next customer from the queue and starts service.
For two staff members, two separate `service_time` variables are maintained, allowing parallel service.
- Customer Arrival
Customer arrivals are determined using a random probability function.- If a generated random number is smaller than `arrival_prob`, a new customer is inserted into the queue.
- Each new customer is assigned a random service time between `1` and `max_serv_time.`
- Statistics Collection
During the simulation, the program tracks:- `customers` total customers arrived
- `served_customers` total customers served
- `waited_time` total waiting time of all customers
At the end, average wait time per customer and remaining queue length are calculated.
When the bank simulation is extended to two staff members, each staff can serve customers independently, which reduces the overall waiting time.
Customers are still queued in a single FIFO line, but with two service counters, the next available staff can immediately attend to the next customer.

This parallel processing allows multiple customers to be served simultaneously, effectively decreasing the average wait time and preventing the queue from growing too long, especially under higher arrival probabilities.
To handle multiple staff, the function `remove_customer()` was overloaded to ` remove_customer(inte teller_id) `


In our simulation with a 70% arrival probability, the average wait time dropped noticeably compared to the single-staff scenario. (To obtain meaningful results, Increase the variable `duration` to 100.)


#5. My Learning Points
In this project, I did not implement the stack and queue from scratch but modified the given code. As a result, I didn’t write much original code, which made me want to try coding it from the beginning next time. If I had implemented it in Java, I would have created staff as objects and allowed them to operate concurrently. Using procedural programming, however, gave me a new perspective: controlling each staff member’s service time and handling completion through functions. I also realized that main should be kept short, so separating the simulation logic into its own function would make the program cleaner and more manageable.
Appendix
- MyGitHub Repository : https://github.com/sihyes/2025-Data-Structures
- About List : https://sihyes.tistory.com/117
'컴퓨터공학과 > Data structures' 카테고리의 다른 글
| [자료구조] Priority, Heap (0) | 2025.11.05 |
|---|---|
| Assignment05 Technical Report (0) | 2025.10.27 |
| [자료구조] List (0) | 2025.10.08 |
| Assignment03 Technical Report (0) | 2025.10.02 |
| Assignment02 _ Technical Report (0) | 2025.09.24 |