Implementation and Analysis of Priority
- Course: Data Structures
- StudentID: 2466044
- Author: LEE SIEUN
- Date: 2025-11-11
- Repository(public): https://github.com/sihyes/2025-Data-Structures/tree/main/06-Priority
#0. Assignment Goals
This report covers priority queues.
1. Using a given skeleton code, randomly generated numbers are sorted using hip-sorts, and execution time is measured.
2. Implement encoding/decoding code using Huffman binary tree.
#1. Introduction(Theoretical Background, Logic)
A priority queue is a data structure where each element has a priority, and elements with higher priority are processed first (not FIFO).
It can be implemented using arrays, linked lists, or heaps.
- Types:
- Min-priority queue (lowest key first)
- Max-priority queue (highest key first)
- Applications:
- Simulation systems (event scheduling)
- Network traffic control
- Operating system job scheduling
Implementation Insertion Deletion
| Unordered array | O(1) | O(n) |
| Ordered array | O(n) | O(1) |
| Heap | O(log n) | O(log n) |
A heap is a complete binary tree that satisfies the heap property:
- Max heap: parent ≥ children
- Min heap: parent ≤ children
- Height of heap = O(log n)
Implementation:
Heaps are stored in arrays (since they are complete trees):
- Parent index = i / 2
- Left child = 2i
- Right child = 2i + 1
Insertion (Max Heap):
Insert at the end, then compare with parent and swap until heap property holds.
Time complexity: O(log n)
Deletion (Max Heap):
Remove root, move last node to root, and sift down.
Time complexity: O(log n)
build max heap
- Can be done in O(n) using a bottom-up approach.
- Process nodes from n/2 down to 1, ensuring that each subtree satisfies the heap property.
- Unlike repeated insertion (O(n log n)), this method builds the heap more efficiently.
Heap Sort is a sorting algorithm based on the max heap.
Procedure:
- Build a max heap from the input array.
- Repeatedly remove the maximum (root) and store it in the array.
Time complexity: O(n log n).
Even if the heap is built in O(n), overall complexity remains O(n log n).
Use case: Efficient when only a few largest (or smallest) values are needed instead of a full sort.
Huffman coding is a lossless data compression algorithm using a binary tree.
Characters are assigned variable-length binary codes based on frequency:
- More frequent characters → shorter codes
- Less frequent characters → longer codes
Steps to Build Huffman Tree:
- Insert all characters with their frequencies into a min heap.
- Repeatedly remove two smallest nodes and merge them into a new node.
- Repeat until only one node remains — the root of the Huffman tree.
Complexity: O(n log n).
Application: Used in formats like JPEG, ZIP, MP3 for optimal encoding.
#2. Problem Definition
1. (Programming: 30 points)
Implement the heap sort by using ‘build_max_heap’ function as below.
- Refer to the attach file (providing the skeleton code).
- Implement ‘build_max_heap’.
- Generate an input array of size 10, 100, 1000, and 5000, and then apply the heap sort and measure the runtime.

2. (Programming: 70 points)
Implement the code for encoding and decoding an input data using Huffman binary tree.
- Refer to the attach file (providing the skeleton code).
- The following functions should be implemented. ‘huffman_traversal’, ‘huffman_encoding’, ‘huffman_decoding’
- It is not mandatory to follow the skeleton code. Feel free to implement your own codes, if needed.

#3. Algorithm and Data Structure
The Heap Sort algorithm was implemented using the Heap data structure in the form of a complete binary tree. The array was first transformed into a max heap (build_max_heap), and elements were then sorted by repeatedly removing the root node.
The program used a Priority Queue and Binary Tree to construct a Huffman Tree based on character frequencies. The input data was then encoded and decoded using variable-length binary codes derived from the tree.
1. 힙 정렬 (Heap Sort)
- 한국어 설명:
완전이진트리 형태의 힙(Heap) 자료구조를 사용하여, 주어진 배열을 최대 힙으로 구성(build_max_heap) 한 뒤, 루트 노드를 하나씩 제거하면서 정렬을 수행하는 힙 정렬 알고리즘을 구현하였다.
2. 허프만 인코딩 및 디코딩 (Huffman Encoding & Decoding)
- 한국어 설명:
문자 빈도수를 기반으로 우선순위 큐(Priority Queue) 와 이진 트리(Binary Tree) 를 사용하여 허프만 트리(Huffman Tree) 를 구성하고, 이를 통해 입력 데이터를 가변 길이 이진 코드로 인코딩 및 디코딩하였다.
#4. Implementation Results and Analysis
4.1 Implementation of `build_max_heap()`
This implementation was written with reference to Deletion in Max Heap on page 17 of the lecture slides.
The key idea of heap sort is to start from the last non-leaf (parent) node, not from the leaf nodes.
Therefore, the process begins from the midpoint of the heap (the last parent node) and proceeds upward to the root in reverse order.
For each parent node, the algorithm compares its key with those of its children.
If the parent’s key is smaller than a child’s key, the two nodes are swapped.
After swapping, the algorithm continues to traverse downward, ensuring that the parent ≥ child property holds throughout the subtree.
Once all comparisons are completed and the heap property is satisfied,
the temporarily stored parent node is placed into its correct position.
The process then repeats for the next parent node (index -1) until the entire heap is built.
void build_max_heap(HeapType *h)
{
// Implement this function here.
//힙은 자료구조 배열을 사용하지.... 즉 자식은 부모*2 [부모 자식1 자식2 자식1-1 자식1-2 자식2-1 자식 2-2 | 1-1-1 | 1-1-2 | 1-2-1] // 뒤에 다섯개가 비교대상
for (int i= h->heap_size/2; i>=1; i--){
int parent = i;
element temp = h->heap[parent];
while (2*parent <=h->heap_size) {
int child = 2*parent;
if ( (child < h->heap_size) && (h->heap[child].key) < h->heap[child+1].key)
child++; // 17page
if (temp.key >= h->heap[child].key) break;
//move dowwn!
h->heap[parent] = h->heap[child];
parent = child;
child *=2;
}
h->heap[parent] = temp; //맨처음 잡아놓은 parent의 위치가 어딘지 파악가능!
}
}
강의자료 17페이지 Deletion in Max Heap 예시를 참고하여 작성하였다.
힙 정렬의 핵심은 리프 노드가 아닌 부모 노드의 마지막 지점에서부터 시작하는 것이다.
따라서, 전체 힙 크기의 절반(즉, 마지막 부모 노드)부터 루트 노드까지 역순으로 이동하며 정렬을 수행한다.
각 부모 노드에 대해, 부모 노드와 그 자식 노드들의 키 값을 비교한다.
만약 부모 노드의 키가 자식 노드보다 작다면, 두 노드의 위치를 교환한다.
이때 교환된 자식 노드가 하위 자식 노드들과의 관계에서도 부모 ≥ 자식 조건을 만족해야 하므로,
하향식으로(leaf까지) 비교를 반복하며 힙 조건을 유지한다.
모든 비교가 끝나고 관계가 만족되면, 최종적으로 해당 위치에 임시로 저장해둔 부모 노드를 삽입한다.
그 후 다음 부모 노드(인덱스 -1)로 이동하여 동일한 과정을 반복한다.
To measure the runtime, I used the #include <sys/time.h> library, which allowed me to measure the execution time for each input size.
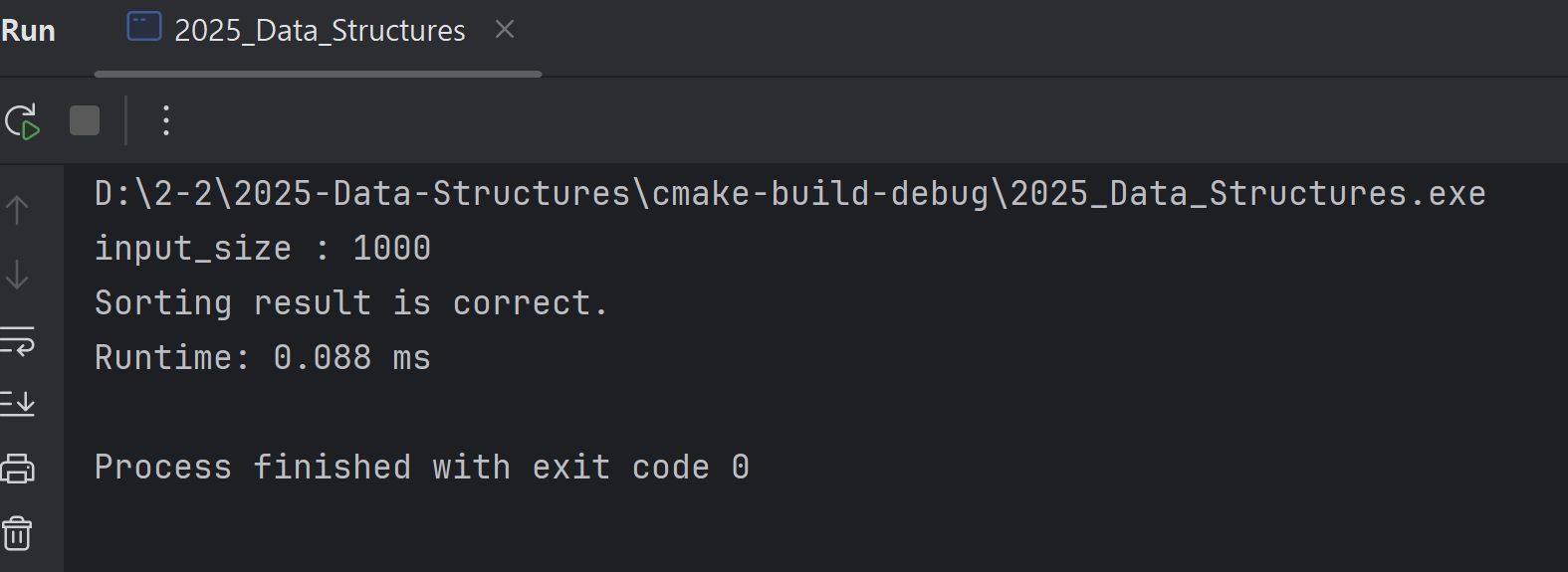
The actual results showed that for an input size of 10, the runtime was 0.001 ms; for 100, it was 0.017 ms; and for 1000, it was 0.088 ms.

struct timeval start, end;
gettimeofday(&start, NULL); // 시작 시간
// Perform the heap sort
heap_sort(h1, output, input_size);
gettimeofday(&end, NULL); // 종료 시간
double runtime_ms = (end.tv_sec - start.tv_sec)*1000.0 + (end.tv_usec - start.tv_usec)/1000.0;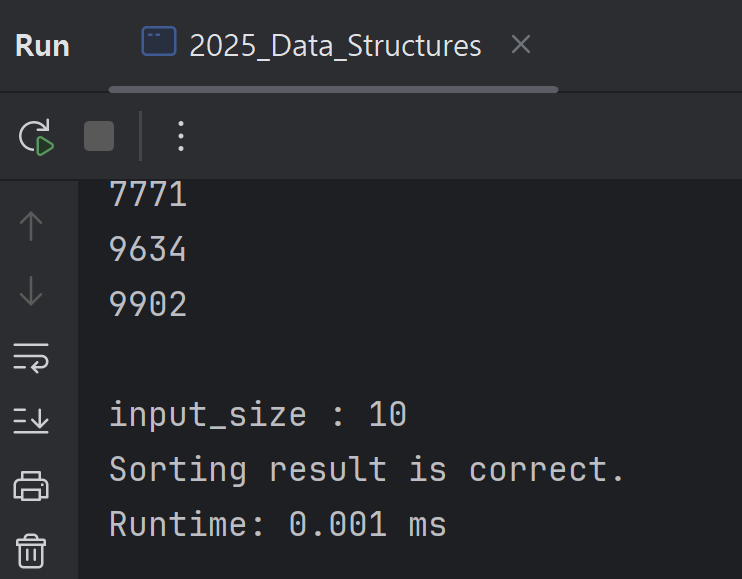


| input_size | runtime (ms) |
| 10 | 0.001 |
| 100 | 0.011 |
| 1000 | 0.088 |
| 5000 | 1.099 |
As the input size increases from 10 → 100 → 1000 → 5000, the runtime grows progressively faster. This behavior aligns with the theoretical time complexity of HeapSort, which is O(n log n).
Specifically, while the input size from 1000 to 5000 increases by a factor of 5, the measured runtime grows by roughly 12 times. This shows that the growth is faster than linear due to the logarithmic component in the time complexity. Although the increase is not perfectly proportional to n log n, the trend confirms that HeapSort’s runtime scales according to its expected complexity.
#4.2 implementation of huffman tree.
first, implementation of `huffman_traversal(TreeNode *node)`.
void huffman_traversal(TreeNode *node)
{
static int code[MAX_BIT]; // 현재까지의 0/1 코드 경로 (유지되어야함 전역으로)
static int depth = 0; // 현재 깊이
if (node == NULL) return; // 종료조건설정
// 리프 노드이면 (== 문자 노드, 종착지 도착)
if (node->l== NULL && node->r == NULL) {
int index = node->data - 'a'; // 'a'~ 순서대로 인덱스, ASCII니까 제일 처음 a 빼주면 인덱스 나온다.
m_bit_size[index] = depth;
// 코드 저장
for (int i = 0; i < depth; i++)
{
m_LUT[index][i] = code[i];
node->bits[i] = code[i]; // TreeNode에도 저장
}
node->bit_size = depth;
return;
}
// 왼쪽 이동 - 0
if (node->l != NULL)
{
code[depth] = 0;
depth++;
huffman_traversal(node->l);
depth--; // 돌아올 때 복원
}
// 오른쪽 이동 -1
if (node->r != NULL)
{
code[depth] = 1;
depth++;
huffman_traversal(node->r);
depth--;
}
}This function recursively traverses the Huffman tree to create codes for each character.
Key points:
- Go left = 0, go right = 1.
- When a leaf node is reached, save the current path as the character’s code.
- depth keeps track of the code length.
- Store the code in a lookup table (m_LUT) and the tree node (node->bits).
- After visiting a child, decrease depth to go back.
// Input: 'str'
// Output: 'bits_stream' (consisting of 0 or 1)
// 'bits_stream' is generated using 'm_LUT' generated by the huffman binary tree
// Return the total length of bits_stream
void huffman_encoding(char *str, bits_stream *bits_str)
{
//...
int interval = 0; // 전체 비트 길이 (결과)
for (int i = 0; i < strlen(str); i++)
{
int index = str[i] - 'a'; // 문자를 인덱스로 ('a'~'f')
int bit_len = m_bit_size[index]; // 코드 길이
for (int j = 0; j < bit_len; j++)
{
bits_str->stream[interval++] = m_LUT[index][j]; // 코드비트를 순서대로 저장
}
}
bits_str->length = interval;
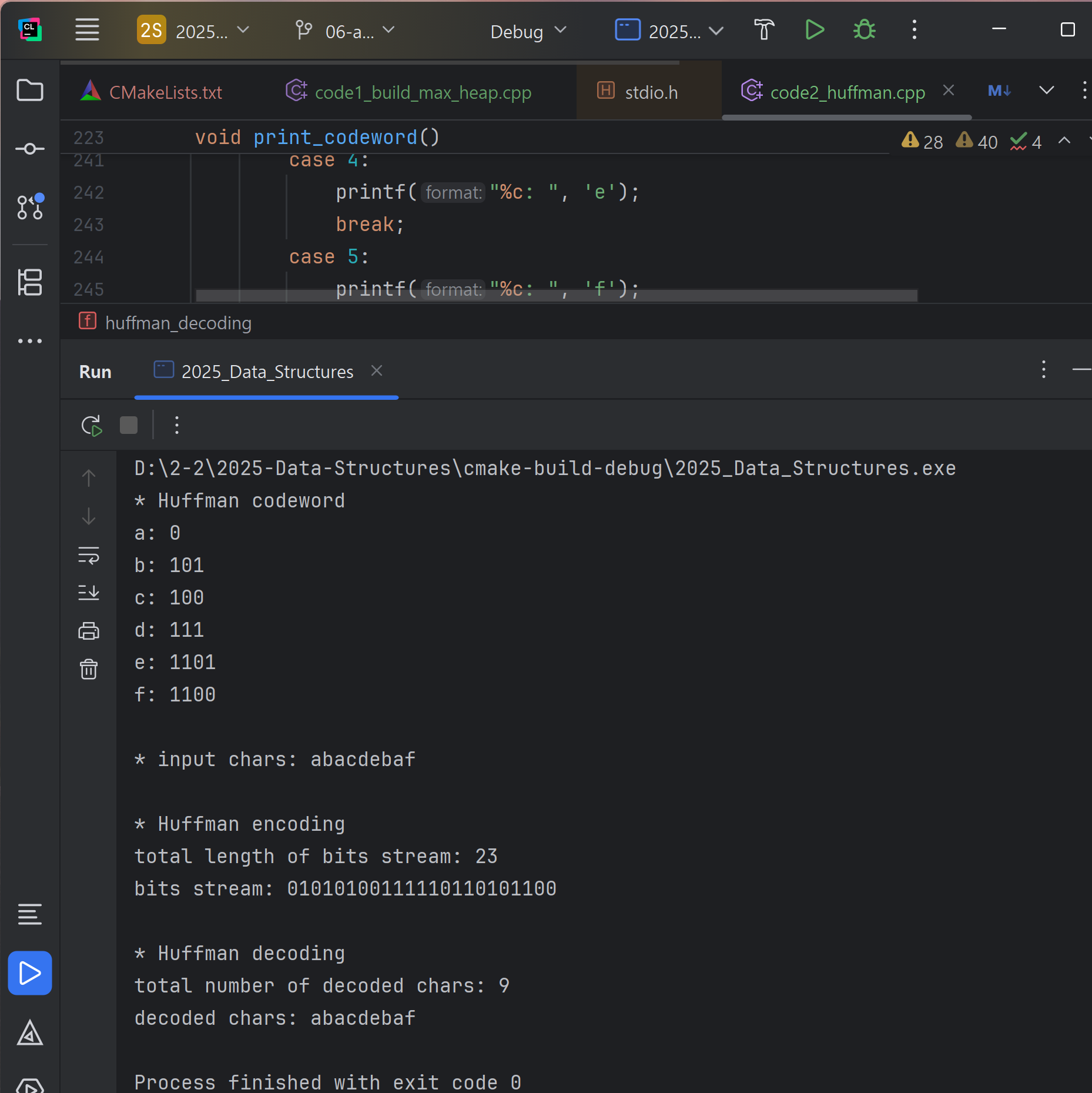
printf("\n* Huffman encoding\n");
printf("total length of bits stream: %d\n", interval);
printf("bits stream: ");
for (int i=0; i < interval; i++)
printf("%d", bits_str->stream[i]);
printf("\n");
}
// input: 'bits_stream' and 'total_length'
// output: 'decoded_str'
int huffman_decoding(bits_stream *bits_str, TreeNode *node, char *decoded_str)
{
//...
TreeNode *cur = node; // 루트부터 탐색 시작 current
int index_char = 0; // 복호화된 문자 개수
for (int i = 0; i < bits_str->length; i++)
{
if (bits_str->stream[i] == 0)
cur = cur->l; // 0이면 왼쪽
else
cur = cur->r; // 1이면 오른쪽
// 리프노드 도착 (문자 발견)
if (cur->l == NULL && cur->r == NULL)
{
decoded_str[index_char++] = cur->data; // 문자 저장
cur = node; // 다시 루트로 돌아가서 다음 문자 탐색
}
}
printf("\n* Huffman decoding\n");
printf("total number of decoded chars: %d\n", index_char);
printf("decoded chars: ");
for (int i = 0; i < index_char; i++)
printf("%c", decoded_str[i]);
printf("\n");
return index_char;
}In Huffman encoding, each character in the input string is mapped to its corresponding Huffman code using the lookup table (`m_LUT`), and each bit of the code is appended in order to the output bit stream while tracking the total length with a counter (`interval`). For decoding, the process starts from the root of the Huffman tree and reads bits from the encoded stream one by one, moving left for `0` and right for `1`. When a leaf node is reached, the corresponding character is recorded, and the traversal returns to the root to decode the next character. This procedure repeats until all bits are processed, reconstructing the original string. The implementation relies on the precomputed codes from the tree traversal for efficient encoding, and the tree structure itself for decoding, ensuring that both processes correctly map between characters and their Huffman codewords.
#5. My Learning Points
Through this assignment, I realized the advantages of implementing a complete binary tree using an array. By using a structure that contains a pointer to a dynamically allocated array, I could access elements like `heap[1]` or `heap[2]`, which made the heap operations straightforward. This highlighted how structures in C can effectively organize data while providing array-like access, even when using pointers. In the second part of the assignment, I encountered many new terms such as lookup tables, which was challenging at first, but studying them helped reinforce my understanding. It was also fascinating to learn that widely used applications, such as JPEG files, utilize similar Huffman encoding and decoding techniques in real life, connecting theoretical concepts with practical applications.
Appendix
- MyGitHub Repository : https://github.com/sihyes/2025-Data-Structures
- About Priority, Heap : https://sihyes.tistory.com/140
'컴퓨터공학과 > Data structures' 카테고리의 다른 글
| Technical report 09 Hashing Search (0) | 2025.12.15 |
|---|---|
| Assignment07 technical report (0) | 2025.11.14 |
| [자료구조] Priority, Heap (0) | 2025.11.05 |
| Assignment05 Technical Report (0) | 2025.10.27 |
| Assignment04_Technical report (0) | 2025.10.10 |