Implementation and Analysis of Hashing & Search
- Course: Data Structures
- StudentID: 2466044
- Author: LEE SIEUN
- Date: 2025-12-15
- Repository(public): https://github.com/sihyes/2025-Data-Structures/tree/main/09-HashingSearch
#1. Introduction(Theoretical Background, Logic)
#1.1 Hashing
Hashing is a method to access items by calculating their addresses (index) in a hash table using an arithmetic operation on the key values.
Key Concepts & Comparison
| Feature | Traditional Search | Hashing |
|---|---|---|
| Logic | Based on comparison with key values | Arithmetic operation on key values |
| Time Complexity | $O(n)$ or $O(log_2 n)$ | $O(1)$ ideally |
| Data Structure | Array, Linked List, Tree | Hash Table (direct access structure) |
Example: Student ID System
- Key: Student ID (e.g., 5 digits: 00023).
- Hash Function: Use the last 3 digits as an index (e.g.,
ht[23]). - Result: If the table has enough space, the search takes $O(1)$ time without collisions.

#1.2 Search
Search is the process of finding specific data from multiple sources. The efficiency depends on whether the data is ordered or unordered.
Search Methods by Data Status
| Method | Data Type | Logic | Time Complexity |
|---|---|---|---|
| Sequential Search | Unordered | Checks every item from the beginning | $O(n)$ |
| Binary Search | Ordered | Repeatedly divides the search range in half | $O(log_2 n)$ |
| Interpolation Search | Ordered | Predicts the location based on key distribution | $O(log_2 n)$ |
| Indexed Sequential | Ordered | Uses an index table to jump to segments | $O(m + n/m)$ |
Key Terminology
- Search Key: A unique identifier that distinguishes items.
- Collision: Occurs when two different keys result in the same hash address.
- Balanced BST (e.g., AVL Tree): Keeps the tree height minimal ($O(log n)$) to ensure efficient searching.
#2. Problem Definition
- (Programming: 50 points)
In p29-31 of ‘DS-Lec11Hashing’, there is no function to delete the item in the hash table. Please implement ‘hash_chain_delete(element item, ListNode *ht[])’, and then test the code with the following commands
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination): 0
Enter the search key: and
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination): 0
Enter the search key: test
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination): 0
Enter the search key: cat
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination): 0
Enter the search key: dna
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination): 0
Enter the search key: nad
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination): 1
Enter the search key: dna- (Programming: 50 points)
Sort an input data using the binary search tree.
- Generate an input array of size 1000 randomly.
- Insert elements in the input array iteratively into the binary search tree.
- Apply the tree traversal to print the sorted results.
(Think about what traversal should be used)
int input_size = 1000;
int data_maxval = 10000;
// output: sorted result
int *input = (int *)malloc(sizeof(int)*input_size);
// Generate an input data randomly for (int i = 0; i < input_size; i++)
input[i] = random(data_maxval);#3. Algorithm and Data Structure
#3.1 default code. & test case
implementation of deletion is also using linked list like insertion.
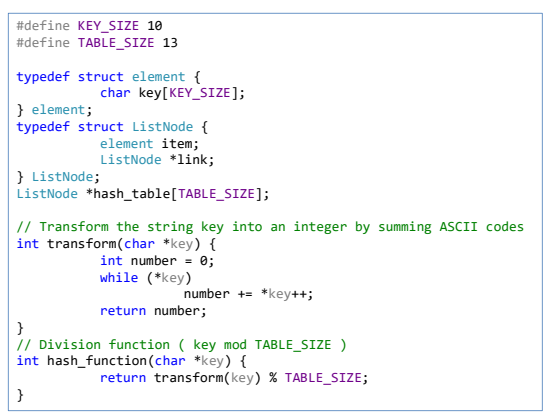


//
// Created by sinil on 2025-12-15.
//
//
#include <cstring>
#include <stdio.h>
#define KEY_SIZE 10
#define TABLE_SIZE 13
typedef struct element {
char key[KEY_SIZE];
} element;
typedef struct ListNode {
element item;
ListNode *link;
} ListNode;
ListNode *hash_table[TABLE_SIZE];
// Transform the string key into an integer by summing ASCII codes
int transform(char *key) {
int number = 0;
while (*key)
number += *key++;
return number;
}
// Division function ( key mod TABLE_SIZE )
int hash_function(char *key) {
return
transform(key)
%
TABLE_SIZE;
}
#define equal(e1, e2) (!strcmp(e1.key, e2.key))
void hash_chain_add(element item, ListNode *ht[]) {
int hash_value = hash_function(item.key);
ListNode *ptr;
ListNode *node_before = NULL;
ListNode *node = ht[hash_value];
for (; node; node_before = node, node = node->link) {
if (equal(node->item, item)) {
fprintf(stderr, "Duplicate search key\n");
return;
}
}
ptr = (ListNode *) malloc(sizeof(ListNode));
ptr->item = item;
ptr->link = NULL;
if (node_before)
node_before->link = ptr;
else
ht[hash_value] = ptr;
}
void hash_chain_search(element item, ListNode *ht[]) {
ListNode *node;
int hash_value = hash_function(item.key);
for (node = ht[hash_value]; node; node = node->link) {
if (equal(node->item, item)) {
printf("Search success\n");
return;
}
}
printf("Search failed\n");
}
void hash_chain_print(ListNode *ht[])
{
ListNode *node;
for (int i = 0; i < TABLE_SIZE; i++) {
printf("[%d]", i);
for (node = ht[i]; node; node = node->link) printf(" -> %s", node->item.key);
printf(" -> null\n");
}
}
void init_table(ListNode *ht[])
{
for (int i = 0; i < TABLE_SIZE; i++)
ht[i] = NULL;//each node is initialized as null
}
void hash_chain_delete(element item, ListNode *ht[]) {
}
int main() {
element tmp;
int op;
init_table(hash_table);
while (1) {
printf("Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination): "); scanf_s("%d", &op);
if (op == 2) break;
printf("Enter the search key: "); scanf_s("%s", tmp.key, sizeof(tmp.key)); if (op == 0)
hash_chain_add(tmp, hash_table); else if (op == 1)
hash_chain_search(tmp, hash_table); hash_chain_print(hash_table);
printf("\n"); }
}출력되어야하는 결과값 예시(insert)

#3.2 Searching.
for the sorting with Binary Search Tree... we should set In-Order Traversal! (by definition. left->root->right)
| Feature | Binary Search Tree (BST) | Max Heap |
|---|---|---|
| Logic | Left < Root < Right | Child nodes $\le$ Parent node |
| Order | Maintains sorted order | Maintains partial order (Max value at root) |
| Sorting | In-order Traversal $\rightarrow$ Ascending | Heap Sort $\rightarrow$ Descending (usually) |
| Search Time | Average $O(\log n)$ | $O(n)$ (not optimized for search) |

#4. Implementation Results and Analysis
4.1 Implementation of `hash_chain_delete(..)` .
The implementation of the `hash_chain_delete` function follows the standard logic of Deleting a Node from a Singly Linked List. To maintain the existing order and prevent data loss, the link of the previous node is reconnected to the link of the target node before the memory is released using `free()`
| Step | Operation | Description |
|---|---|---|
| 1. Search | node_before, node | Traverse the list to locate the target key. |
| 2. Relink | node_before->link = node->link | Bypass the target node by connecting the previous node to the next. |
| 3. Handle Head | ht[hash_value] = node->link | If the target is the first node, update the head pointer. |
| 4. Free | free(node) | Deallocate the memory to prevent memory leaks. |
.
void hash_chain_delete(element item, ListNode *ht[]) {
int hash_value = hash_function(item.key);
ListNode *node_before = NULL;
ListNode *node = ht[hash_value];
for (; node; node_before = node, node = node->link) {
if (equal(node->item, item)) {
printf("found node! : %s \n", node->item.key);
if (node_before == NULL)
// 케이스 1: 삭제할 노드가 리스트의 첫 번째인 경우 !!! (이전노드가 널이니까 헤드포인터를 뒤로 연결해줘!)
ht[hash_value] = node->link;
else
node_before->link = node->link ; // 삭제하려는 노드의 링크를 이어줍니다.
free(node);
return;
}
}
printf("해당하는 아이템을 찾을 수 없습니다. 삭제를 종료합니다.");
}Test Results
for the exact result, test print String is changed like this.

Result 1: Insertion Test (Success)
After inserting multiple keys, the hash table correctly handles collisions using chaining, forming linked lists at each index.
- Input: "and, "test", "cat", "dna", "nad" (where `and`, `dna`, and `nad` hash to the same index)
- State: [8] -> and -> dna -> nad -> NULL

Result 2: Deletion Test (Success)
When a key is deleted, the pointers are successfully rearranged without breaking the rest of the chain.
- Operation: Delete "dna"
- State: [8] -> and -> nad - >NULL ( link relation is changed, memory freed)

D:\2-2\2025-Data-Structures\cmake-build-debug\2025_Data_Structures.exe
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination):0
Enter the search key:and
[0] -> null
[1] -> null
[2] -> null
[3] -> null
[4] -> null
[5] -> null
[6] -> null
[7] -> null
[8] -> and -> null
[9] -> null
[10] -> null
[11] -> null
[12] -> null
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination):0
Enter the search key:test
[0] -> null
[1] -> null
[2] -> null
[3] -> null
[4] -> null
[5] -> null
[6] -> test -> null
[7] -> null
[8] -> and -> null
[9] -> null
[10] -> null
[11] -> null
[12] -> null
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination):0
Enter the search key:cat
[0] -> cat -> null
[1] -> null
[2] -> null
[3] -> null
[4] -> null
[5] -> null
[6] -> test -> null
[7] -> null
[8] -> and -> null
[9] -> null
[10] -> null
[11] -> null
[12] -> null
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination):0
Enter the search key:dna
[0] -> cat -> null
[1] -> null
[2] -> null
[3] -> null
[4] -> null
[5] -> null
[6] -> test -> null
[7] -> null
[8] -> and -> dna -> null
[9] -> null
[10] -> null
[11] -> null
[12] -> null
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination):0
Enter the search key:nad
[0] -> cat -> null
[1] -> null
[2] -> null
[3] -> null
[4] -> null
[5] -> null
[6] -> test -> null
[7] -> null
[8] -> and -> dna -> nad -> null
[9] -> null
[10] -> null
[11] -> null
[12] -> null
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination):1
Enter the search key:dna
found node! : dna
[0] -> cat -> null
[1] -> null
[2] -> null
[3] -> null
[4] -> null
[5] -> null
[6] -> test -> null
[7] -> null
[8] -> and -> nad -> null
[9] -> null
[10] -> null
[11] -> null
[12] -> null
Enter the operation to do (0: insert, 1: delete, 2: search, 3: termination):
#4.2 Implementation of BST and In-Order traversal
A. Iterative Insertion with Pointer Tracking
- Instead of using recursion, a while loop was used to navigate to the correct leaf position.
- A trailing pointer (p) was essential to keep track of the parent node, allowing us to attach the new node to the NULL spot.
B. Handling Duplicate Keys
- To ensure no data is lost among 1,000 random inputs, the condition `key >= p->key` was applied.
- This logic consistently pushes duplicate values to the right subtree, preserving them for the final output.
C. Sorting via In-order Traversal
- The most critical point for sorting is the In-order Traversal (Left $\rightarrow$ Root $\rightarrow$ Right).
- Because of the BST property, this specific traversal naturally visits every node in ascending order, completing the sort without additional algorithms.
D. Memory Management & Scalability
- Using the iterative approach prevents Stack Overflow errors that can occur with deep trees (especially with large datasets like 1,000 elements).
- Dynamic memory allocation (malloc) was used to handle the input array and tree nodes efficiently.
After right insertion, we can easily get the ascending order results.


below is the whole code
//
// Created by sinil on 2025-12-15.
//
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
// 1. ㅌ트리노드 구조체 정의
typedef struct TreeNode {
int key;
struct TreeNode *left, *right;
} TreeNode;
// 새 노드 생성 함수
TreeNode* create_node(int key) {
TreeNode* temp = (TreeNode*)malloc(sizeof(TreeNode));
temp->key = key;
temp->left = temp->right = NULL;
return temp;
}
// 2. BST 삽입 함수 iteratively!
void insert_iterative(TreeNode** root, int key) {
TreeNode* p = NULL; // 부모 노드를 추적
TreeNode* t = *root; // 현재 탐색 노드
TreeNode* new_node; // 새로 생성할 노드
// 새 노드 생성
new_node = create_node(key);
// 1. 삽입할 위치 탐색
while (t != NULL) {
p = t; // 현재 노드를 부모로 설정하고 아래로 이동
if (key < t->key)
t = t->left;
else
t = t->right; // 중복 값도 오른쪽으로 이동
}
// 3. 트리가 비어있었다면 루트로 설정
if (p == NULL)
*root = new_node;
else {
// 부모 노드와 뉴 노드 연결
if (key < p->key)
p->left = new_node;
else
p->right = new_node;
}
}
// 3. 중위 순회 (In-order Traversal)
void inorder(TreeNode* root) {
if (root != NULL) {
inorder(root->left); // 왼
printf("%d ", root->key); // 루트
inorder(root->right); // 오른
}
}
int main() {
int input_size = 1000;
int data_maxval = 10000;
TreeNode* root = NULL;
//시드 시간으로
srand(time(NULL));
// 공간을 할당해줘용
int* input = (int*)malloc(sizeof(int) * input_size);
printf("Generating and inserting 1000 random numbers...\n");
for (int i = 0; i < input_size; i++) {
input[i] = rand() % data_maxval; // 0 ~ 9999 사이 난수
insert_iterative(&root, input[i]); // 즉시 BST에 삽입
}
// 4. 결과 출력
printf("\nSorted Results (In-order Traversal):\n");
inorder(root);
printf("\n");
free(input);
return 0;
}#5. My Learning Points
Through this implementation, I had the chance to clarify the concepts of Heaps and BSTs, which I had previously found confusing. It was a great opportunity to solidify my understanding by coding them myself.
One of the most fascinating realizations was how fundamental structures like Linked Lists and Arrays are consistently utilized in more advanced data structures. I now feel confident that mastering Linked Lists is the key to solving various complex implementation problems in the future.
Appendix
- MyGitHub Repository : https://github.com/sihyes/2025-Data-Structures
- About Tree : https://sihyes.tistory.com/136
- About List: https://sihyes.tistory.com/117
'컴퓨터공학과 > Data structures' 카테고리의 다른 글
| Assignment07 technical report (0) | 2025.11.14 |
|---|---|
| Assignment06 Technical Report (0) | 2025.11.10 |
| [자료구조] Priority, Heap (0) | 2025.11.05 |
| Assignment05 Technical Report (0) | 2025.10.27 |
| Assignment04_Technical report (0) | 2025.10.10 |